If you are a software engineer or a programmer you must have used stackoverflow atleast once in your life time. But have you ever wondered how stackoverflow predicts the tags for a given question ? In this blog, I will discuss about stackoverflow tag predictor case study.
Github code repo: stackoverflow tag preditor
Problem Statement
Predict the tags (a.k.a. keywords, topics, summaries), given only the question text and its title.
Read the full problem statement on kaggle
Business Objectives and Constraints
- Predict tags with high precision and recall
- No strict latency constraints.
Machine Learning Problem
Data
Data contains 4 fields
-
Id - Unique identifier for each question
-
Title - The question’s title
-
Body - The body of the question
-
Tags - The tags associated with the question
Click here for more details.
Size of Train.csv - 6.75GB
Number of rows in Train.csv = 6034195
P.S:There are two files: Train.csv & Test.csv. Based on the computing power of my system, I have taken only a subset of data from Train.csv
Sample data point
Id: 5
Title: How to modify whois contact details?
Body:
<pre>
<code>
function modify(.......)
{
$mcontact = file_get_contents( "https://test.httpapi.com/api/contacts/modify.json?auth-userid=$uid&auth-password=$pass&contact-id=$cid&name=$name &company=$company&email=$email&address-line-1=$street&city=$city&country=$country&zipcode=$pincode&phone-cc=$countryCodeList[$phc]&phone=$phone" );
$mdetails = json_decode( $mcontact, true );
return $mdetails;
}
</code>
</pre>
<p>using this modify function, displays warning mesage</p>
<pre class="lang-none prettyprint-override">
<code>
Warning: file_get_contents(https://...@hihfg.com&address-line-1=3,dfgdf,fgdf&city=dfgfd&country=India&zipcode=641005&phone-cc=91&phone=756657)
[function.file-get-contents]: failed to open stream: HTTP request failed!
HTTP/1.0 400 Bad request in /home/gfdgfd/public_html/new_one/customer/account/class.whois.php on line 49\n
</code>
</pre>
<p>Please help me, modify contact details.</p>
Tags: php api file-get-contents
Mapping the Business problem to a Machine Learning Problem
Type of Machine Learning Problem
It is a multi-label classification problem.
In Multi-label Classification, multiple labels (in this problem its tags) may be assigned to each instance and there is no constraint on how many of the classes the instance can be assigned to. Source: Wiki
Find more about multi-label classification problem here
A question on Stackoverflow might be about any of C, Pointers, JAVA, Regex, FileIO and/or memory-management at the same time or none of these.
Performance metric
- Micro F1 score
- Macro F1 score
I have discussed in detail about the performance metrices in my previous blog post. Please read this blog to know more about Micro & Macro F1 scores.
EDA (Exploratory Data Analysis)
I have used pandas library to load the data. Please visit my github repo to see the full code. I have taken a sample of 1000000 (10 lakh) data points from Train.csv. Here is a list of major observations from EDA.
- Number of rows in the database: 1000000
- 5.6% of the questions are duplicate: Number of rows after removing duplicates: 943582
- Number of unique tags: 34945
-
Top 10 important tags: [‘.a’, ‘.app’, ‘.aspxauth’, ‘.bash-profile’, ‘.class-file’, ‘.cs-file’, ‘.doc’, ‘.drv’, ‘.ds-store’, ‘.each’]
- Few number of tags have appeared more than 50000 times & the top 25 tags have appeared more than 10000 times
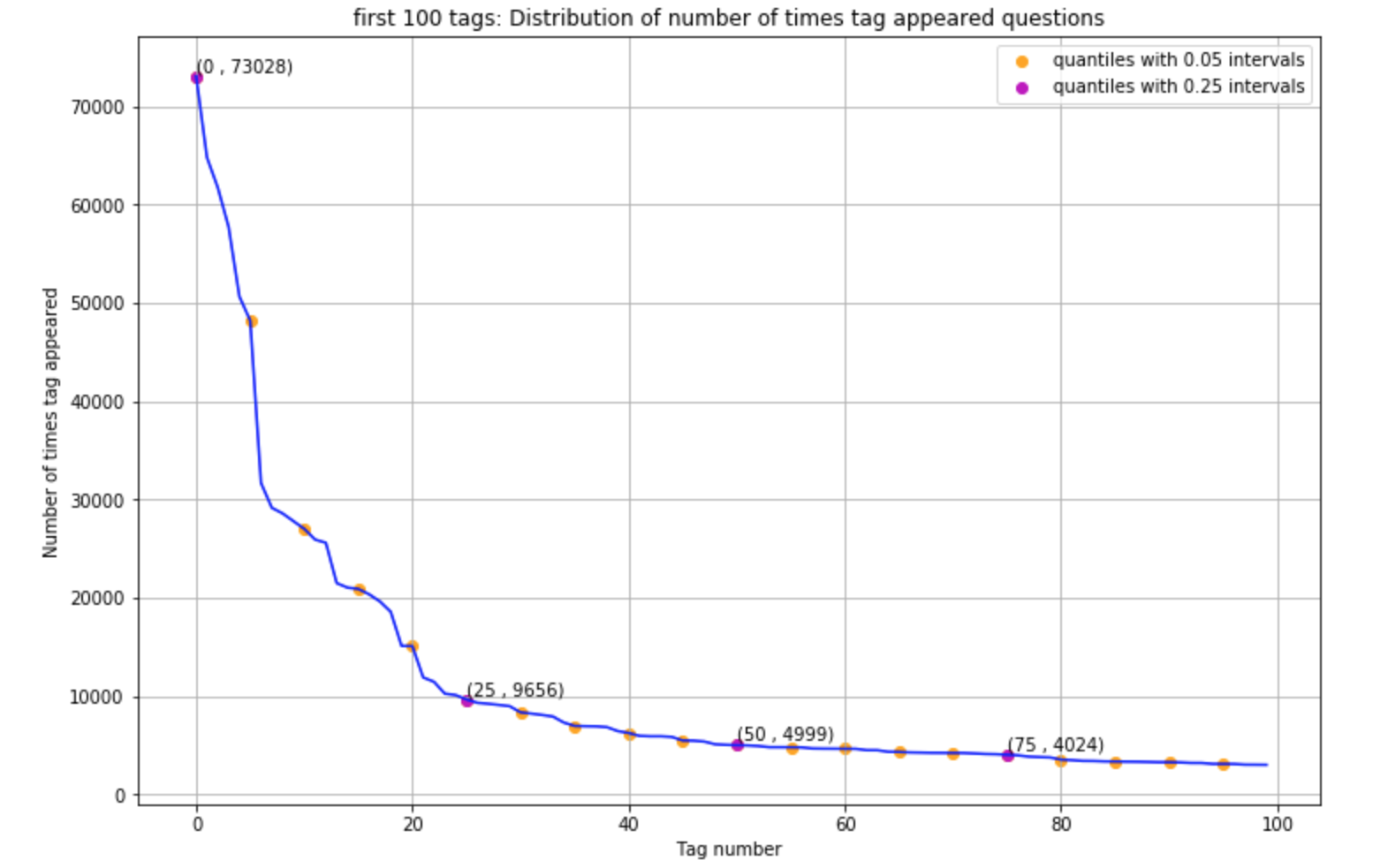
- Tags analysis
- Maximum number of tags per question: 5
- Minimum number of tags per question: 1
- Avg. number of tags per question: 2.887779
- Questions with 3 tags appeared more in number
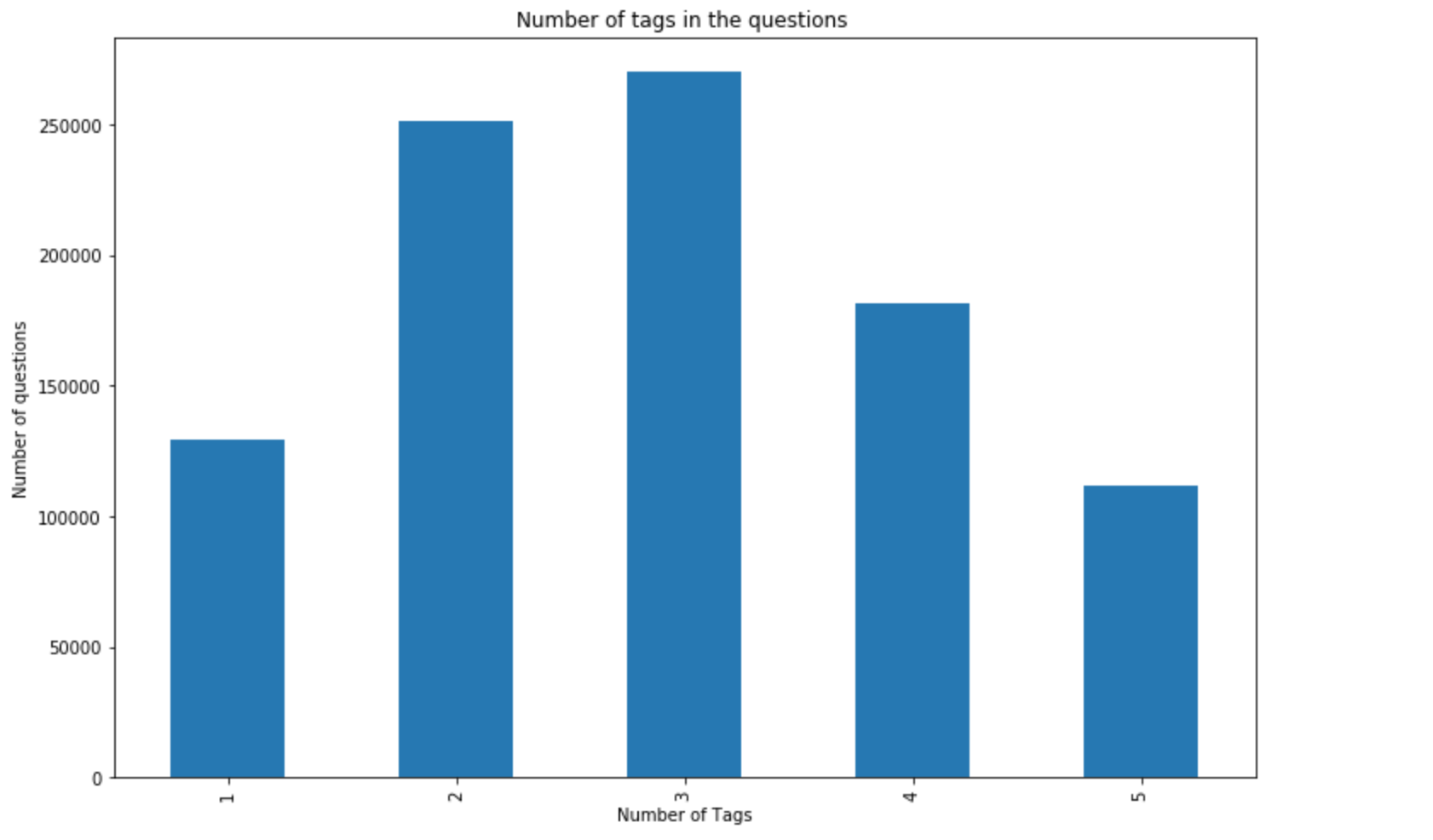
- Word cloud of tags
 6.
6.C#appears most number of times,Javais the second most. Majority of the most frequent tags are programming language. And here is the chart for top 20 tags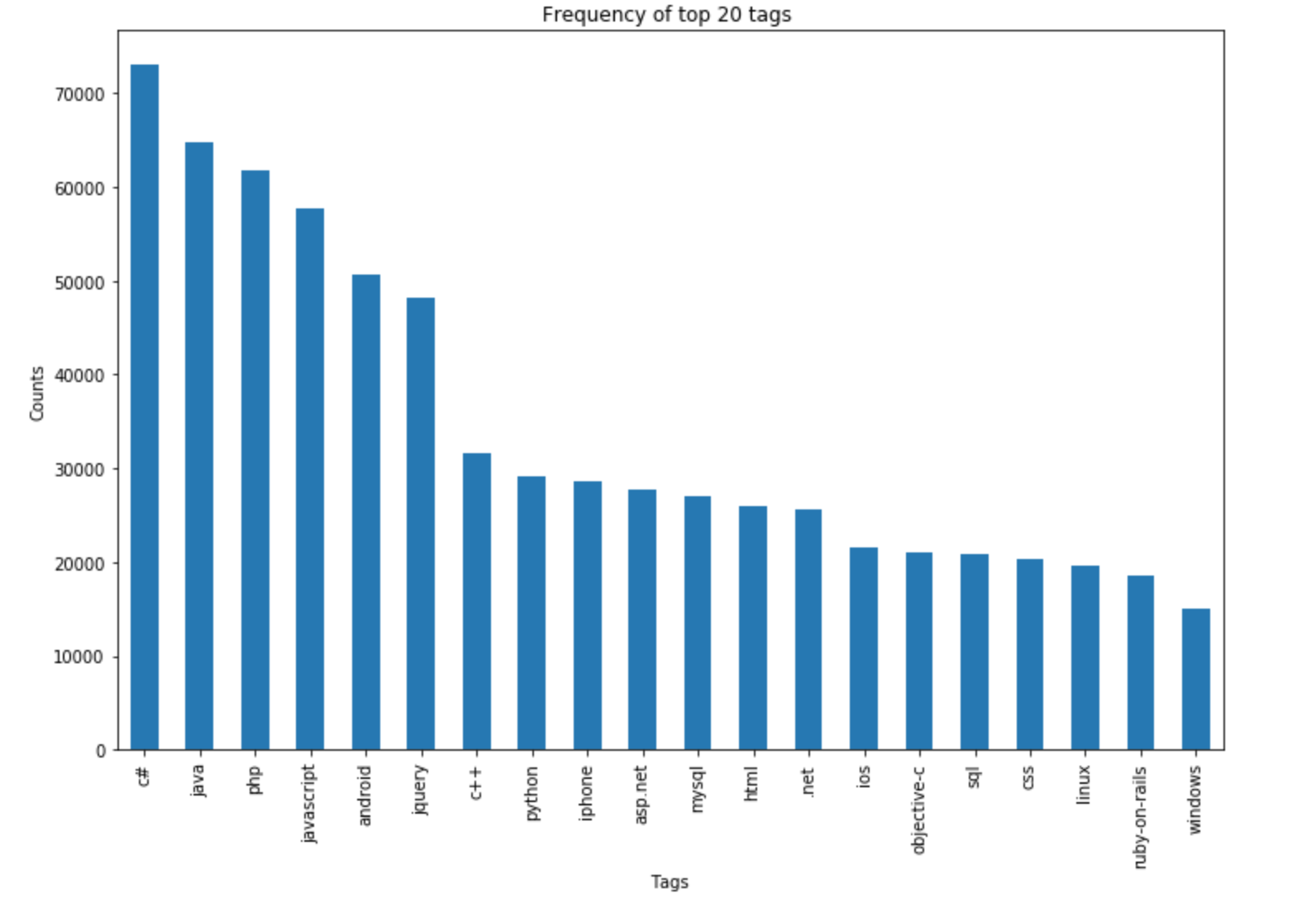
Cleaning and preprocessing of Questions
P.S: Due to hardware limitations, I am considering only 500K data points
preprocessing
- 56.37% percentage of questions contains HTML tag <code> tag. So separate out code-snippets from the Body
- Remove Spcial characters from title and Body (not in code)
- Remove stop words (Except 'C')
- Remove HTML Tags
- Convert all the characters into small letters
- Use SnowballStemmer to stem the words.
Stemming is the process of reducing a word to its word stem.
For Example: "python" is the stem word for the words ["python" "pythoner", "pythoning","pythoned"] - Give more weightage to title: Add title three times to the question. Title contains the information which is more specific to the question and also only after seeing the question title, a user decides whether to look into the question in detail. At least most of the users do this if not all
Sample question after preprocessing:
“modifi whoi contact detail modifi whoi contact detail modifi whoi contact detail use modifi function display warn mesag pleas help modifi contact detail”
Machine Learning Models
Total number of questions: 500000
Total number of tags: 30645
Here we are going to use Problem Transformation(Binary Relevance) method to solve the problem.
Binary Relevance:
Here we are going to convert multi-label classification problem into multiple single class classification problems.For example if we are having 5 multi-label classification problem, then we need to train 5 single class classification models.
Basically in this method, we treat each label (in our case its tag) as a separate single class classification problem. This technique is simple and is widely used.
Please refer to analytics vidhya’s blog to know more about the techniques to solve a Multi-Label classification problem.
Downscaling of data
Coming back to our stackoverflow predictor problem, we need to train 30645 models literally!!! Thats really huge (both in terms of time & speed) for a system with 8GB RAM & i5 processor. So we will sample the number of tags instead considering all of them. But how many tags to be sampled with the minimal information loss ? Plotting ‘percentage of questions covered’ Vs ‘Number of tags’ would help to solve this.
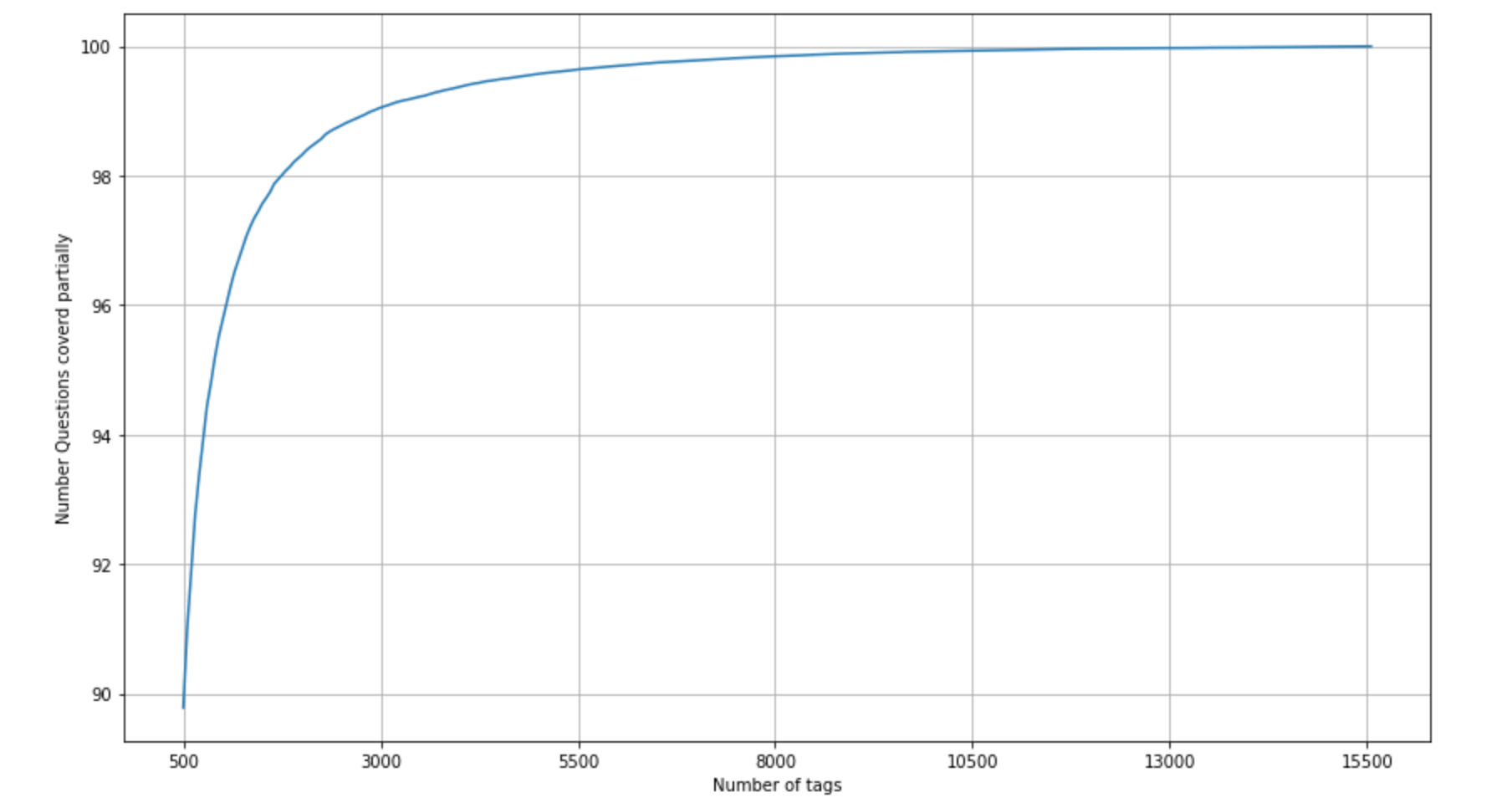
Observations
- with 500 tags we are covering 89.782 % of questions
- with 600 tags we are covering 91.006 % of questions
- with 5500 tags we are covering 99.053 % of questions
By choosing only 600 tags (2% approximately) of the total 30645 tags we are loosing only 9% of the questions & also training 600 models is reasonable (Of course it also depends on the type of machine learning algo we choose). So we shall choose 600 tags.
Train and Test data
If the data had timestamp attached for each of the questions, then splitting data with respect to its temporal nature would have made more sense than splitting data randomly. But since the data is not of temporal nature (i.e., no timestamp), we are splitting data randomly into 80% train set & 20% test set
train_datasize= 0.8 * preprocessed_title_more_weight_df.shape[0]
x_train = preprocessed_title_more_weight_df[:int(train_datasize)]
x_test = preprocessed_title_more_weight_df[int(train_datasize):]
y_train = multilabel_yx[0:train_datasize,:]
y_test = multilabel_yx[train_datasize:,:]
Featurizing Text Data with TfIdf vectorizer
There are various ways to featurize text data. I have explained this deeply in my blog post. First lets featurize the question data with TfIdf vectorizer. TfidfVectorizer of sklearn helps here
vectorizer = TfidfVectorizer(min_df=0.00009, max_features=200000, smooth_idf=True, norm="l2",sublinear_tf=False, ngram_range=(1,3))
x_train_multilabel = vectorizer.fit_transform(x_train['questions'])
x_test_multilabel = vectorizer.transform(x_test['questions'])
Dimensions of train data X: (400000, 90809) Y : (400000, 600)
Dimensions of test data X: (100000, 90809) Y: (100000, 600)
Applying Logistic Regression with OneVsRest Classifier (for tfidf vectorizers)
Lets use Logistic Regression algo to train 600 models (600 tags). We shall use OneVsRestClassifier of sklearn to achieve the same
classifier = OneVsRestClassifier(LogisticRegression(penalty='l1'), n_jobs=-1)
classifier.fit(x_train_multilabel, y_train)
predictions = classifier.predict(x_test_multilabel)
Results
Micro F1-measure: 0.4950
Macro F1-measure: 0.3809
Featurizing Text Data with Bag Of Words (BOW) vectorizer
This time lets featurize the question data with BOW upto 4 grams.
I did try Featurizing Text Data with Bag Of Words, but my system was giving out of memory error. So again I have to downscale the data to 100K. Here is train & test data after downscaling
Dimensions of train data X: (80000, 200000) Y : (80000, 600)
Dimensions of test data X: (20000, 200000) Y: (20000, 600)
vectorizer = CountVectorizer(min_df=0.00001,max_features=200000, ngram_range=(1,4))
x_train_multilabel = vectorizer.fit_transform(x_train['questions'])
x_test_multilabel = vectorizer.transform(x_test['questions'])Applying Logistic Regression with OneVsRest Classifier (for BOW vectorizers)
classifier = OneVsRestClassifier(LogisticRegression(penalty='l1'))
classifier.fit(x_train_multilabel, y_train)
predictions = classifier.predict(x_test_multilabel)Results
Micro F1-measure: 0.4781
Macro F1-measure: 0.3655
Hyperparameter tuning on alpha for Logistic Regression to improve performance
I did tried tuning the Hyperparameter alpha for Logistic Regression, but I didn’t find any significant improvement (or even small improvement) in the performance, either in micro-f1 score or macro f1-score
OneVsRestClassifier with Linear-SVM
Lets use Linear-SVM algo to train 600 models. Linear-SVM is nothing but SGDClassifier with loss as hinge. After finding the hyperparameter alpha using GridSearchCV , I found out alpha to be 0.001
classifier = OneVsRestClassifier(SGDClassifier(loss='hinge', alpha=grid_search.best_params_['estimator__alpha'], penalty='l1', max_iter=1000,tol=0.0001 ), n_jobs=-1)
classifier.fit(x_train_multilabel, y_train)
predictions = classifier.predict(x_test_multilabel)Results
Micro F1-measure: 0.4007
Macro F1-measure: 0.2430
Observations
Of all the models we used so far, Logistic Regression with TfIdf vectorizer and n_grams=(1,3) performed better than rest of the models. But we have trained the Logistic Regression model with large number of data points, so comparing this model with rest the models, which are trained with lesser data points, will not make sense. So we need to train Logistic Regression model with TfIdf vectorizer & n_grams=(1,3) with 100K data points. So the comparision between the models will be reasonable
Here is the result of all the models
| Model Used | Number of Data Points Used | F1-micro score | F1-macro score |
|---|---|---|---|
| Logistic Regression (with TfIdf vectorizer, n_grams=(1,3)) | 500K | 0.4950 | 0.3809 |
| Logistic Regression (with TfIdf vectorizer, n_grams=(1,3)) | 100K | 0.4648 | 0.3391 |
| Logistic Regression (with BOW vectorizer, n_grams=(1, 4), alpha=1) | 100K | 0.4781 | 0.3655 |
| Logistic Regression (with BOW vectorizer, n_grams=(1, 4), alpha = 6 (from hyperparameter tuning)) | 100K | 0.4774 | 0.3676 |
| Linear-SVM (with BOW vectorizer, n_grams=(1, 4)) | 100K | 0.4007 | 0.2430 |
| Linear-SVM (with tfidf vectorizer, n_gram=(1, 3)) | 100K | 0.4648 | 0.2900 |
Logistic Regression (with BOW vectorizer, n_grams=(1, 4), alpha=1) performed better than rest of the models
Problem with complex models like Random Forests or GBDT ?
As you might have noticied, I have taken simplest model like Logistic Regression & Linear SVM to train the model. Here is the two primary main reasons why the complex models were not tried
- High dimentional data: since we are converting text to TfIdf or BOW vectors, the dimensions we get are very large in size. And when the dimensions are large, typically Random Forests & GBDT won’t work well.
- Too many models to train: We have literally 600 models to train (after downscaling of data). And Logistic Regression is the simplest model one can use & it is comparitively faster. If we start using other models like RBF-SVM or RF, it will take too much time to train the model. For me it took more than 16 hours of time to train Linear SVM, that too after downscaling of data by large margin
Enhancements:
- To try with more data points (on a system with 32GB RAM & highend processor)
- Featurizing Text Data with Word2Vec: When you try Word2Vec, the dimentionality of data reduces & hence complex models like Random Forests or GBDT might work well
- Try using scikit-multilearn library. Please note that this library doesn’t take sparse matrix as input, you need to give dense matrix as input.So obviously you need to have more RAM to use this library
Any input/suggestions are most welcome @Kalsi
Thank you for reading