In order to apply any Machine Learning algorithm, we have to convert all non-numerical data to numerical data.
Here I am going to discuss some of the methodolgies to convert text data into numerical vectors. A vector is nothing but a numerical array. Please look into Linear Algebra section to know more about vectors & their properties.
Also by converting text data to numerical array, we can measure similarity between the texts by using Euclidean distance or Cosine similarity
Lets consider the following example.
-
text1: India is a beautiful country
-
text2: I am proud of my country
BOW model (Bag Of Words)
In this model, each text data is converted to a vector whose length is equal to number of unique words in the whole document. Initially each value in the vector is initilised to zero.
For both text1 & text2, the vector looks as follows initially
| I | India | a | am | beautiful | country | is | my | of | proud |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
Calculate BOW values
For each of the word in the text_data:
increase the count of the word by 1
(i) text1: (India is a beautiful country)
| I | India | a | am | beautiful | country | is | my | of | proud |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 0 | 0 |
(ii) text2: (I am proud of my country)
| I | India | a | am | beautiful | country | is | my | of | proud |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 1 | 1 |
If we have very large number of unique words, then the size of the vector will be very large
TF - IDF (Term frequency - Inverse Document Frequency)
TF (Term Frequency)
TF is measured for a word in the text data. TF for a word in text data is the probability of that word in the text data.i.e.,
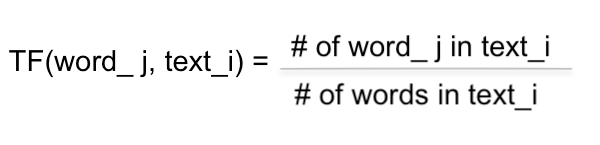
IDF (Inverse Document Frequency)
IDF is measured for a word with respect to the whole document. IDF of a word \(W_j\) is defined as the log of total number of documents in the corpus to the number of documents that contains the word \(W_j\). i.e.,
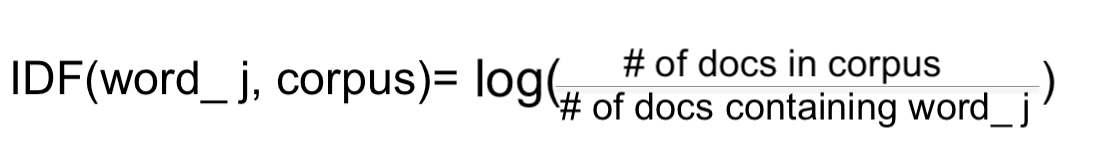
TF-IDF
It is the product of TF & IDF of a word.
So TF-IDF value balances between the rare words in the document & highly frequent words in the corpus. High value of IDF indicates, the word occurs very few times in the whole document corpus. And a high value of TF indicates, the word occurs more number of times in the text document.
- TF-IDF Vector representation of text1 (India is a beautiful country)
Similary we can calculate TF-IDF values for other words. So TF-IDF vector for text1 can be represented as follows
| I | India | a | am | beautiful | country | is | my | of | proud |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.06 | 0.06 | 0 | 0.06 | 0 | 0.06 | 0 | 0 | 0 |
There are also many variations of TF-IDF model like TF-IDF word2vec model. I will discuss word2vec in Deep Learning section (…coming soon…)